| Next Page | Prev Page | Main Index | Home |
Next Paradigm Systems has developed a method by which databases
can be created using the native operating system as the core of
a database management system (DBMS). Such a database architecture
when using a massively parallel cluster of I/O processors,
has no hard limits to speed, size, maximum users,
reliability, or recovery options. No architectural limits to
when or how much capacity and/or performance can be added to an
I/O cluster. It is now possible to start considering your corporate
information based on business need rather than on computing or
traditional database constraints.
Skip ahead to PERFORMANCE SCALABILITY,
DATA SCALABILITY, ACCESS SCALABILITY,
RELIABILITY, DATA COMPRESSION,
STORING DATA AS INFORMATION,
STORAGE MEDIA PERFORMANCE,
DISTRIBUTED MODEL, SECURITY,
HARDWARE COST, ARCHITECTURE,
ACCESSABLILITY, EXAMPLE.
Use the browser back button to return.
In traditional DBMS's, a single set of difficult tradeoffs is
the inevitable result of any database design. This means that
design considerations have been driven by the database's
limitations. The Next Paradigm Systems approach puts the focus
on the system goals, not on the limits. Each new component builds
on, or in parallel with, the rest of the system. Each MPbase
is created to grow and change without the normal pain factor.
The method used to access the data is neither fixed nor limited
to a single choice. The MPbases developed to date have
used three or more parallel access methods to a single copy of
the same data at the same time. Each individual access method
can then be tuned and optimized for the applications it is supporting.
Select one point in each range | Indicate importance of each |
0 . . 1 . . 2 . . 3 . . 4 . . 5
0 . . 1 . . 2 . . 3 . . 4 . . 5 . . . | Online . . . . (0,5) ______ Batch . . . . .(0,5) ______ Recovery . . (0,5) ______ Through-put (0,5) ______ . . . |
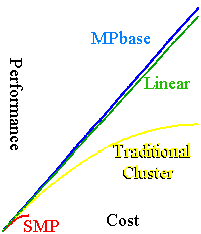
With most clustered architectures, linear scaling is a much sought
after, yet never achieved, computational Holy Grail. MPbase
generally exhibits better than linear scaling. The
more I/O processors an MPbase cluster contains, the faster
each processor will run. This is only possible with an architecture
driven from the bottom up (pull) not the top down. As the number
of I/O processors continues to increase, the scaling may eventually
fall back to linear, but never less.
Performance of an MPbase I/O cluster is primarily determined
by the amount of disk space given to each I/O processor node (disk/processor
ratio). This factor is determined independently of data capacity
and access capacity, and can be changed independently as well.
This means that a performance level can be set that will not degrade
as more capacity is added to the MPbase. This ratio determines
the performance for the worst case query. All other cases will
show improvement with size. With MPbase the bigger it is,
the faster it runs!
There is no performance penalty for adding hardware to an MPbase
I/O cluster. There is no architectural upper limit to
the size of a table in an MPbase. After the initial disk-to-processor
ratio is set, the number of disk/processor sets (nodes) needed
is then determined by the amount of data to be stored. This means
that to add more data, add more nodes. A single query will never
be slower after adding more nodes and will most often run faster.
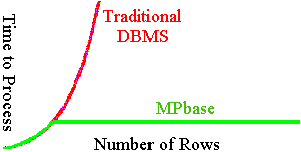
The two-part Achilles heel of most conventional large databases
is fragmentation and the reorganization
required to correct it (or, for that matter any process requiring
a full sequential scan). With MPbase, once the disk/processor
ratio is determined, the time needed to perform any full database
process will be no more than the time needed at a single node.
This time will NOT increase as the database grows.
A table of 100 billion rows will reorganize as fast as the number
of rows found on a single node. Once again, as MPbase grows,
the worst-case-processing times will not increase. All other processing
cases just keep getting faster with size.
The architecture of MPbase allows a true many-to-many network
between the nodes holding the data and the nodes providing user
access. This means MPbase has no single choke point. This
lack of a single access/choke point allows the I/O cluster to
be scaled to ANY level of parallel access. This also allows parallel
access to scale independently of data scaling and performance
scaling.
The architecture allows a single database image with no single
choke point. This means creating a database with NO LIMITS.
A database which will start at any requested level of performance.
A database to which you can predictably add any amount of storage,
parallel access and/or performance. A database which can start
small and gracefully grow to ANY size providing ANY desired performance
level with ANY degree of parallel access.
MPbase can be configured to be fault-tolerant at the node
level. With a massively parallel platform, fault tolerance is
not an option. MPbase can be implemented with no single
failure point. The loss of ANY one user or data node in the MPbase
I/O cluster need not stop it from functioning nor cause any data
to become inaccessible.
The architecture is such that an MPbase need never go down.
Backups, restores and even re-organizational unload/reloads, do
not require queries or transaction processing to be stopped. Depending
on requirements and MPbase's I/O cluster design, even updates
can continue during such processing.
All data and data types stored in MPbase are kept internally
in a highly compressed common format. The compression method,
which is lossless in nature and unique to MPbase, is called
"Multidimensional Data-Intelligent Run Length Encoding."
Think of this as computer-readable shorthand. This allows even
faster access to the compressed data than would be possible
for the uncompressed data. Typical compression rates can be 60%
to 99% over a flat ASCII (text) file. The resulting physical format
is directly usable on any hardware capable of running MPbase.
The compression format by itself provides a good level of both
security and data integrity. If required, the low-level access
routines can include varying additional levels of encryption parallelized
across multiple nodes. The function handling the compression also
provides access or update monitoring and/or control through a
single low-level routine. Access to the database can then be as
open or as controlled as required.
In MPbase, the data is transformed inside the low level
objects into information. This can best be described as a formless
format. From this state, the data can be recreated in any required
output format. There is no performance penalty for this activity.
As a matter of fact, this reformatting is used to increase performance
while at the same time significantly decreasing the physical storage
requirements.
This data storage technique allows the direct linking of any tables
containing the same "information." Internally, the external
format is irrelevant. The key values are meaningless until converted
by each table's access code. This puts all of the information
stored in MPbase into the same information space. The only
time the external data format is used is in the final result set
to be sent to the user, without regard to EBCDIC vs. ASCII vs.
proprietary formats. On the inbound side, the external format
is lost just as quickly. It is converted to an internal transfer
format before being passed to the data nodes for storage in the
formless common format.
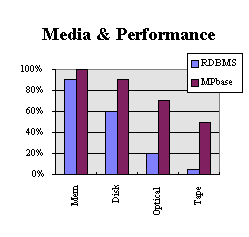
The storage media model changes
significantly with the implementation of MPbase. It is
possible to view optical or tape media in a much improved light
as they relate closer to the performance of magnetic disk and
memory.
In comparison with conventional databases, memory is faster, disk
is as fast as memory was, and optical is faster than disk was.
The loosely coupled architecture lends itself to a unique set
of implementations. For instance, there is no requirement that
the nodes making up an I/O cluster be in the same room or even
at the same site. This same freedom exists in relation to second
or even third copies of the same data when running mirrored. Think
of the possible benefits to having a single consistent database
image based on hardware placed all over the world. Each branch
could maintain its own portion of the corporate data, while at
the same time corporate headquarters would have a company-wide
view. The possible configurations are as endless as real world
business requirements dictate.
For extreme reliability, MPbase can be run with distributed
mirrored copies at multiple sites with each site kept in update
synchronization in real time. The queries can be distributed to
the site currently running with the least load. This distribution
can occur at the sub-query level allowing all sites to work on
parts of a single query as the load permits. In this configuration
the failure of any one node or even one entire site need not affect
the ability to continue to run queries.
Security in a networked environment is a major concern. MPbase
has two operational models to address this. The open model which
is used with non-secure data and/or on a protected internal network.
Or, at the other end of the spectrum, the secure model can be
configured to meet any possible requirements.
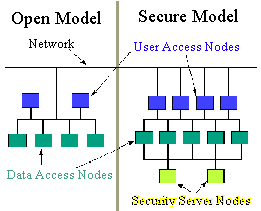
In the open model, the access routines can be stored and backed
up with the data requiring no keys and operating from the command
line. In this mode, the compression functions as just that: compression.
The only side benefit is data integrity. Think of this model in
the same light as a self-extracting archive. If it is corrupt,
it will tell you. If it is not corrupt, it is usable on its own.
And now, really good news! MPbase loves small inexpensive
workstation class machines. Because of the fault-tolerance at
the node level, there is no need for special high-reliability
fault-tolerant equipment. Also, because there is no penalty for
adding nodes, there is no need for the premium-priced, high-end
SMP platforms. The main criterion for an efficient hardware selection
is dollars per unit of useful work.
When redundancy is required, the combination of the compression
and the ability to use less expensive hardware really adds up.
A configuration using two copies of the data will typically have
an aggregate compression (including the space used by both copies)
of 60% to 80% or better. Based on this type of compression multiple
mirrored copies become a very cost effective option.
The "magic" that makes all of this possible is a massively
parallel, object-oriented architecture that can best be described
as inside-out. The database exists, not "inside" a black
box, but "outside" in the operating system's environment.
The MPbase architecture is much like the operating system
(OS) itself. It is made up of lots of little independent pieces.
Each of these pieces communicates to the others through the file
system interface. The result is a system that can take full advantage
of all of the OS features and functions.
What Next Paradigm Systems has developed is a method by which
such a database system, spread out across several machines can
act as if it were a single black box. At the same time allowing
the system to run as fast as if it were an embedded or stand alone
system. When used with "Multidimensional Data-Intelligent
Run Length Encoding," the resulting performance is nearly
unbelievable.
Due to the "inside-out" architecture this database is
directly accessible by any program or system that can use the
OS file system interface. It has been accessed by using: Structured Query Language (SQL),
World Wide Web (HTML), shell scripts, command line and custom
programs of any language. Cross platform access is accomplished
using HTML, RPCs or sockets. All of these are available on virtually
any computing platform.
And now, some details for those into numbers. One MPbase, built
for less than $500,000.00 on thirty workstation nodes, contains
over 50 billion 84-byte rows. It is designed to grow to over 150
billion. This database runs 24 hours a day, seven days a week,
with no downtime. The access rate is over 90 thousand rows, selected,
sorted, and returned per second. This rate involves a key hit
rate of only 25%. So the database is handling 360 thousand keys
per second. This extract rate is maintained in parallel with a
150-row-per-second insert rate, and a 50-row-per-second update
rate.
The internal processing rate, available to "next generation" applications, is over 5 million rows per second, or 18 billion rows per hour. The compression achieved in this database is 95% for a single copy. Counting both the primary and mirror copies the compression is still 90%. This database system lacks any single failure point.
| Next Page | Prev Page | Main Index | Home | © 1998-2004 NPSI |